Vmware ESX Server Backup
Amanda Enterprise 3.0 allows you to backup Vmware ESX images to various media supported by Amanda. The backups are performed in an application consistent manner. These backups can be used for restoration of guest VMs running on the ESX server and can be restored to alternate ESX server.
Guest VM files will have to restored from the restored VMs. Zmanda recommends using Amanda client to backup files from guest VM if file level backup of VMs is needed.
Amanda Enterprise Vmware ESX application supports licensed versions of Vmware ESX 3.5 and 4 (Vsphere 4). Free version of Vmware ESX requires manual steps at the time of restoration.
Requirements for Vmware Server Backup and Restore
- All Amanda Enterprise 3.0 and Zmanda Management Console patches must be installed on the Amanda server.
- Make sure Amanda Enterprise server and Zmanda Management Console is functional before installing and configuring Vmware ESX application.
- Amanda Vmware ESX application agent performs the backup from the Amanda server. No additional Amanda clients are required in the process.
- Amanda server must be running Linux distribution listed on the Zmanda Network Supported Platforms page.
- Following packages must be installed on the Amanda server for Amanda Vmware ESX application:
fuse-libs
fuse
xinetd
Vmware VCLI
Vmware VDDK
fuse-libs and fuse are required by Vmware commands. They can be installed using yum or yast or apt-get tools available in the Linux distribution. Following command shows how to install these packages on RHEL 5 distribution.
# yum install fuse-libs fuse
Vmware VCLI and Vmware VDDK packages are available in the Vmware web site.
- Amanda Vmware ESX application requires temporary space to store the backup images on the Amanda server. The space required should be equal to the size of the guest VM images being backed up. This space requirement is temporary and required only during backup. The amandabackup user should be able to read and write to this directory on the Amanda server.
Installation
Amanda ESX Vmware application must be installed on the Amanda server. Download the ESX Vmware application from the Zmanda Network and extract the tar ball. Run the install.sh script.
Configuring Vmware Server Backups
Configuring Vmware guest VM backups requires steps in both Zmanda Management Console and some manual steps.
- Zmanda recommends creation of separate backup set for backing up guest VM images.
- Create a backup set for the guest VMs in the Zmanda Management Console.
- Configure Backup devices in the Admin Devices page and bind them to the backup set in the Backup Where page.
- Configure minimal staging area in the Backup Where page. Using staging area for the VMware ESX backups does not add any value.
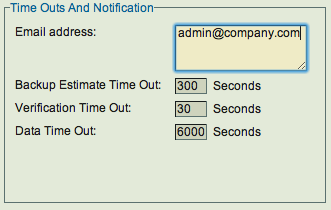
- Change the Data Timeout value in the Backup How page for the backup set. The value should be increased to at least 14400 seconds. Increasing the value does not impact the backup window (time to complete the backup).
- Modify the /etc/amanda/<backup set name>/disklist.conf to add backup entries for each guest VM that has to be backed up. You can have multiple entries in the file.
- Create the ESX authentication file in /etc/amanda/<backup set name>/esxipass . This file should have the ip address for the ESX server, user name and password for the root user. This should be readable only by amandabackup user.
- Before scheduling backups, it is important to verify the Vmware ESX application configuration. Run amcheck command to verify the configuration.
$ amcheck -c <backup set name>
Please resolve any configuration errors found.
For PostgreSQL backups, the data timeout must be increased in the Backup How page. The default data timeout is not sufficient. The data timeout is specified for the backup set and cannot be specified for each Disk List Entry. Zmanda recommends the data timeout should be set to 6000 seconds or higher as shown below. Please note the setting the time out higher will not impact backup performance.
Configuring Vmware Server Restores from the ZMC Restore What Page
Make sure that PostgreSQL is installed in the same location as when the backup was run. The databases and logs file locations should also match the original configuration.
Either select the desired PostgreSQL backup from one of the Reports, or go directly to the Restore Where page and select a PostgreSQL backup for restore. The Explore button lets you select from the most recent backups.
When you have selected the backup object that includes the PostgreSQL server for restore, the Restore What page displays the following options:
.png)
Select the databases you wish to restore. Choose All for a full restore up to the last backup. Click Next Step when you are done, and the Restore Where options are displayed:
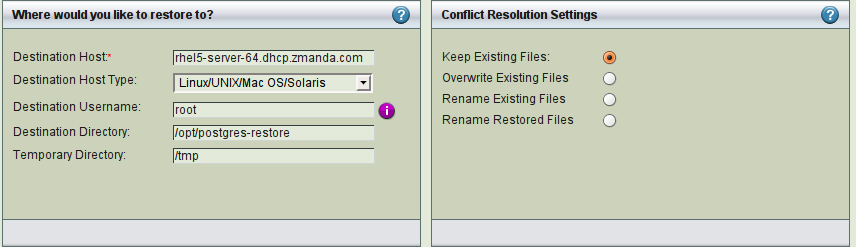
Set the restore options as desired. Note that the Destination Directory and Temporary Directory much each have enough space to hold the selected backup data. If you choose the same directory for both, make sure that the selected directory has enough space to hold two copies of the backup image. Do not specify specify the PostgreSQL data/cluster directory as a destination, especially if PostgreSQL is running.
After reviewing the entries, click Restore to start the restore process.
When the ZMC restore process is complete, the restored files will reside on the specified host and destination directory. Completing the recovery is accomplished outside the ZMC using the host operating system and PostgreSQL as described below.
Completing the PostgreSQL Database Point-in-time Recovery
This section describes the steps to do point-in-time recovery using the database and WAL logs restored using ZMC. You can perform database restoration using amrecover command which is described in the next section.
- If the PostGreSQL server is running, stop it using the following command:
# /etc/init.d/pgplus_83 stop
- As a safeguard, copy the entire cluster data directory from the stopped production server to a temporary location. This will require enough disk space on the system to hold two copies of the existing database. If sufficient disk space is unavailable, you should at the very least make a copy of everything in the pg_xlog subdirectory of the cluster data directory. pg_xlog may contain logs that were not archived before the system was stopped. For example:
mkdir /opt/postgres-restore/safeguard cp -rp /opt/PostgresPlus/8.3/data/ /opt/postgres-restore/safeguard - Remove all files and subdirectories under the cluster data directory.
# rm -rf /opt/PostgresPlus/8.3/data/*
- Using the restored database dump, restore the database files by unpacking the earliest (i.e. the base or level 0) backup image:
# cd /opt/postgres-restore/
# ls
data zmc_restore_20090327141718 zmc_restore_20090329142314
# tar xfv zmc_restore_20090327141718
archive_dir.tar
data_dir.tar
The earliest backup image (zmc_restore_20090327141718 in this case) may be removed if space is needed.
--Unpack the data_dir.tar file to the database data directory
# cd /opt/PostgresPlus/8.3/data/
# tar xf /opt/postgres-restore/data_dir.tar
-- Ensure that all files and directories are restored with the correct ownership (i.e., owned by the database system user, not by root) and permissions.
-- unpack "archive_dir.tar" file and all remaining incremental PostgreSQL backup images to a temporary archive directory owned by the database system user
# mkdir /opt/postgres-restore/archive/
# chown postgres:postgres /opt/postgres-restore/archive/
# cd /opt/postgres-restore/archive/
# tar xf /opt/postgres-restore/archive_dir.tar
# tar xf /opt/postgres-restore/zmc_restore_20090329142314
# ls
00000002000000000000004A 00000002000000000000004B
-- The data_dir.tar, archive_dir.tar and all Postgres backup images may all be deleted now if desired.
- Purge any logs in pg_xlog/; these are from the backup dump and unlikely to be current. If you create a copy of pg_xlog/ in step 2, create it now, taking care to ensure that it is a symbolic link if the original was configured as such. If manually creating the pg_xlog/ directory, you must also recreate the subdirectory pg_xlog/archive_status/ as well.
# rm /opt/PostgresPlus/8.3/data/pg_xlog/*
# rm /opt/PostgresPlus/8.3/data/pg_xlog/archive_status/*
- If you copied the unarchived WAL segment files as described in step 2, copy them now to pg_xlog/. You should copy them rather move them in case there is a problem that requires you to start over.
# rm -rf /opt/PostgresPlus/8.3/data/pg_xlog
# cp -rp /opt/postgres-restore/data/pg_xlog/ /opt/PostgresPlus/8.3/data/
- Create the file recovery.conf in the cluster data directory (see the PostgreSQL documentation's Recovery Settings). It is also prudent to modify pg_hba.conf to prevent users from connecting before successful recovery has been verified.
- Edit /opt/PostgresPlus/8.3/data/recovery.conf to include (at minimum) the following entry, which must specify the path to your temporary archive directory:
restore_command = 'cp /opt/postgres-restore/archive/%f "%p"'
- Change the ownership and permissions on this file so that it is owned by the database system user, and that it is only readable and writable by this user
# chown postgres:postgres /opt/PostgresPlus/8.3/data/recovery.conf
# chmod 0600 /opt/PostgresPlus/8.3/data/recovery.conf
- Start the server, which will automatically begin recovering from the archived WAL files. If the recovery stops on an error, restart the server to continue the recovery after you have corrected the error condition. Upon successful completion of the recovery, the server renames recovery.conf to recovery.done and then starts normal database operations.
# /etc/init.d/pgplus_83 start
- Inspect the the database to verify that it is in the expected point in time. If it is not recovered to the correct point, return to step 1. After the recovery is verified, allow end-user access by restoring pg_hba.conf to to its production state. Further details on PostgreSQL Point-in-time recovery are available in the PostgreSQL documentation; see Recovering using a Continuous Archive Backup.
Vmware server recovery using amrecover command
Instead of using Zmanda Management Console, you can recover PostgreSQL database backups to the client by running amrecover command on the client. The procedure is to restore the database to an alternate location or directly to the database directory (default /var/lib/pgsql). PostgreSQL database will perform the recovery when the service is started. Recovery from WAL can also performed using recovery.conf as described in the previous section.
An example of recovery using amrecover command from a full backup. For complete set of amrecover command options, please see amrecover man page. This steps are valid for RedHat Enterprise Linux/Cent OS. Other platforms will require modifications to the PostgreSQL service name and database directory location.
- Stop the PostgreSQL service
# service postgresql stop
- Copy the PostgreSQL database directory if the data is being restored the database directory.
- Remove all the contents of the Postgres database directory (/var/lib/pgsql)
- Run amrecover on the backup set containing PostgreSQL database
# amrecover <backup set name>
- Select the backup image to be restored
amrecover> setdisk <DLE-name>
- Select the name of the backup file
amrecover> add <name of Postgres backup file>
- Switch the directory to be restored to
amrecover> lcd /var/lib/pgsql
- Start the restoration process
amrecover> extract
- Exit amrecover command
amrecover> quit
- Delete the PostgreSQL Backup label file
# rm /var/lib/pgsql/data/backup_label
- [OPTIONAL] This step is required only for point-in-time recovery. Create the file recovery.conf in the data directory (see the PostgreSQL documentation's Recovery Settings). It is also prudent to modify /var/lib/pgsql/pg_hba.conf to prevent users from connecting before successful recovery has been verified.
- Edit /var/lib/pgsql/data/recovery.conf to include (at minimum) the following entry, which must specify the path to your temporary archive directory:
restore_command = 'cp /var/lib/pgsql/archive/%f "%p"'
- Change the ownership and permissions on this file so that it is owned by the database system user, and that it is only readable and writable by this user
# chown postgres:postgres /var/lib/pgsql/data/recovery.conf
# chmod 0600 /var/lib/pgsql/data/recovery.conf
- Start the PostgreSQL service. PostgreSQL will start recovering the database.
# service postgresql start
Troubleshooting
If the checks or backups are failing due to Postgresql login problems, check that the pg_hba.conf file (a PostgreSQL configuration file located in in the database cluster's data directory) is set up to allow the amandabackup user to log in to the database using the PG-USER and PG-PASSWORD specified. For further information, see the following PostgreSQL documentation:
http://www.postgresql.org/docs/8.3/static/client-authentication.html
http://www.postgresql.org/docs/8.3/static/auth-methods.html#AUTH-IDENT-MAPS